包含树,图,bfs,dfs,最短路径,最小生成树等常用模版代码
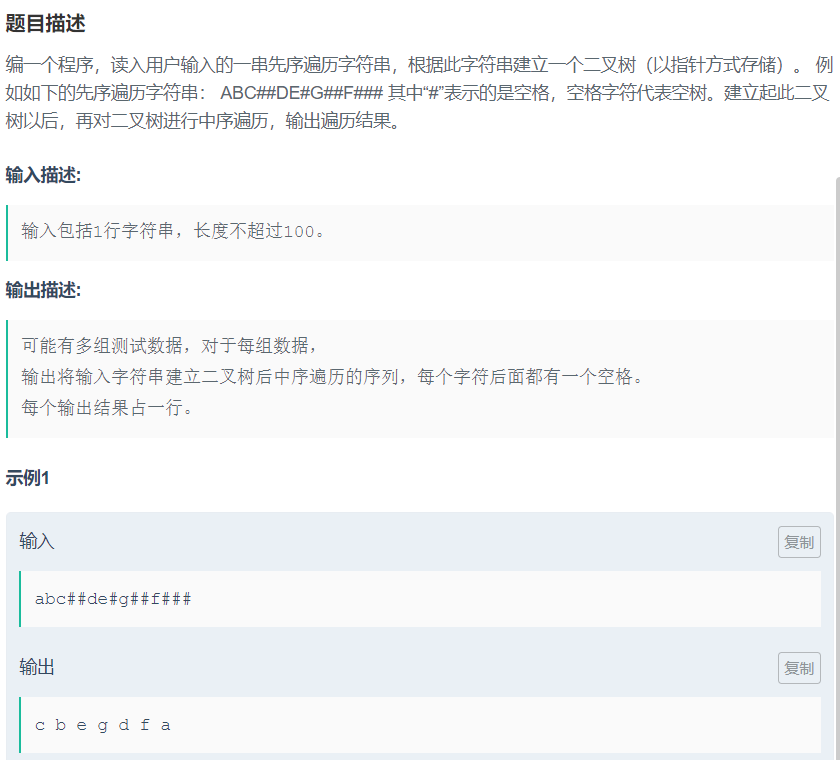
二叉树 题目1:遍历二叉树
利用结论:二叉树的先序遍历入栈,那么出栈顺序就是他的中序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> #include <string> #include <stack> using namespace std;int main () while (cin >> pre)char > s;for (auto it : pre)if (it != '#' )push (it);else if (!s.empty ())top () << ' ' ;pop ();'\n' ;
使用数组模拟二叉树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <stdlib.h> const int N1=1e8 +5 ;const int N2=1e2 +5 ;int pos,len,t;char tree[N1];char str[N2];void create (int pos) char c = str[t++];if (c == '#' )return ;create (pos*2 );create (pos*2 +1 );void traverse (int root) if (tree[root]==0 )return ;traverse (2 *root);printf ("%c " ,tree[root]);traverse (2 *root+1 );int main () while (scanf ("%s" ,str)!=EOF)0 ;create (1 );traverse (1 );printf ("\n" );
通过指针创建二叉树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <stdio.h> #include <stdlib.h> #include <string.h> #define N 101 struct Node {char c;Node *CreateNode () malloc (sizeof (Node));NULL ;NULL ;return ret;void InOrder (Node *T) if (T->lchild!=NULL ) InOrder (T->lchild);printf ("%c " , T->c);if (T->rchild!=NULL ) InOrder (T->rchild);void Del (Node *T) if (T->lchild!=NULL )Del (T->lchild);NULL ;if (T->rchild!=NULL )Del (T->rchild);NULL ;free (T);unsigned pos;char str[N];Node *BuildTree () if (pos>=strlen (str)) return NULL ;if (str[pos]=='#' )return NULL ;CreateNode ();BuildTree ();BuildTree ();return p;int main () while (gets (str))0 ;BuildTree ();InOrder (T);printf ("\n" );Del (T);
题目二:给定先序中序求后序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream>include <algorithm>Post(string str1 ,string str2 ) if (str1.length() ==0 ) return;int root=str2.find(str1[0 ] );Post(str1 .substr (1,root ) ,str2.substr(0 ,root));Post(str1 .substr (root +1) ,str2.substr(root+1 ));[0 ] ;int main() string str1,str2;while (cin>>str1>>str2)Post(str1 ,str2 ) ;
代码二
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <stdio.h> #include <string.h> struct Node char c; 50 ]; int loc; Node *creat () NULL ; return &Tree[loc++]; char str1[30 ], str2[30 ]; void postOrder (Node *T) if (T->lchild != NULL )postOrder (T->lchild); if (T->rchild != NULL )postOrder (T->rchild); printf ("%c" , T->c); Node *build (int s1, int e1, int s2, int e2) creat (); int rootIdx;for (int i = s2; i <= e2; i++)if (str2[i] == str1[s1])break ;if (rootIdx != s2)build (s1 + 1 , s1 + (rootIdx - s2), s2, rootIdx - 1 ); if (rootIdx != e2)build (s1 + (rootIdx - s2) + 1 , e1, rootIdx + 1 , e2); return ret; int main () while (scanf ("%s" , str1) != EOF)scanf ("%s" , str2); 0 ; int L1 = strlen (str1);int L2 = strlen (str2); build (0 , L1 - 1 , 0 , L2 - 1 ); postOrder (T); printf ("\n" ); return 0 ;
图论 vector在邻接链表中的应用 首先定义一个结构体
1 2 3 4 typedef Struct Edge{int nextNode;int cost;
为每一个结点建立一个单链表来保存与其相邻的边权值和结点的信息。使用vector来模拟这些单链表。结点数量为N
利用
1 2 3 for (int i=0 ;i<N;i++) {[i] .clear ();
来实现对这些单链表的初始化
1 2 3 4 Edge tmp= 3 = 38 1 ].push_back(tmp)
当需要查询某个结点的所有邻接信息时,对vector进行遍历
1 2 3 4 for (int i=0 ;i<edge [2 ].size ();i++){int nextNode=edge [2 ][i].nextNode ; int cost=edge [2 ][i].cost ;
当需要删除某个单链表中的某些边信息时,调用vector::erase
1 2 edge[1] .erase (edge[1] .begin ()+i ,edge[1] .begin ())+i +1 );.erase (vector.begin ()+第一个要删除的元素编号,vector.begin ()+最后一个要删除元素的编号+1 )
并查集 首先,定义一个数组,用双亲表示法来表示各棵树(所有的集合元素个数总和为N):
用Tree[i]来表示结点i的双亲结点,若Tree[i]为 -1 则表示该结点不存在双亲结点,即结点i为其所在树的根节点.
1 2 3 4 5 6 int findRoot (int x) if (Tree[x]==-1 ) return x;else return findRoot (Tree[x])
为了优化路径压缩
1 2 3 4 5 6 7 8 9 int findRoot(int x ) if (Tree[x ] ==-1 ) return x;else {int tmp=findRoot(Tree[x ]) ;[x ] =tmp;
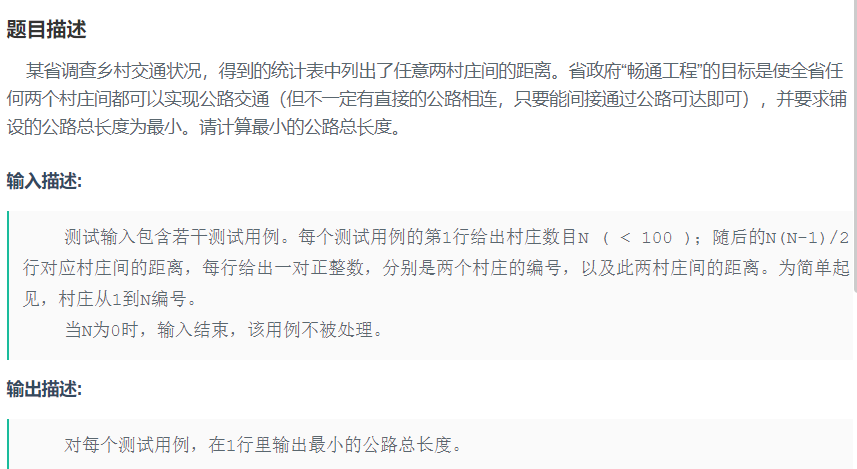
例1 畅通工程 求解图上连通分量个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include<iostream> using namespace std ;int Tree[1010 ];void init ()for (int i=0 ;i<1010 ;i++)-1 ;int findRoot (int xif (Tree[x]==-1 ) return x;else int tmp=findRoot(Tree[x]);return tmp;int main ()int N,M;while (cin>>N&&N)init ();while (M--)int a,b;int roota=findRoot(a);int rootb=findRoot(b);if (roota!=rootb)int ans=0 ;for (int i=1 ;i<=N;i++)if (Tree[i]==-1 ) ans++;-1 <<endl; return 0 ;
例2 More is better 题目大意:有10000000个人,其中有n个好朋友,朋友关系具有传递性,找出最大的集合,集合中都是朋友关系或者只有一个人,输出集合中最多少人。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <iostream> using namespace std ;const int N = 10000001 ;int Tree[N] = {0 };int Sum[N] = {0 };void init ()for (int i = 0 ; i < N; i++)-1 ;1 ;int getRoot (int xif (Tree[x] == -1 )return x;else int tmp = getRoot(Tree[x]);return tmp;int main ()int n;while (cin >> n && n)int a, b;init ();while (n--)if (a!=b)int ans = 1 ;for (int i = 0 ; i < N; i++)if (Tree[i] == -1 )if (Sum[i] > ans)
可以用来判断连通图
最小生成树 定义:在一个无向连通图中,如果存在一个连通子图包含原图中所有的结点合萼部分边,且这个子图中不存在回路,那么我们称这个子图为原图的一颗生成树。在带权图中,所有的生成树中边权的和最小的那颗(或几颗)被称为最小生成树。
Kruskal算法 原理:
初始时所有结点属于孤立的集合
按照边权递增顺序遍历所有的边,若遍历到的边两个顶点仍分属不同的集合(该边即为连通这两个集合的边中权值最小的那条)则确定该边为最小生成树上的一条边,并将这两个顶点分属的集合合并。
遍历完所有边后,原图上所有结点属于同一个集合则被选取的边和原图中所有结点构成最小生成树;否则原图不连通,最小生成树不存在。。
例题1 还是畅通工程,利用并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> #include <algorithm> using namespace std;struct Edge {int a;int b;int cost;5000 ]={0 };int Tree[101 ]={0 };void init () for (int i=0 ;i<101 ;i++)-1 ;int findFather (int x) if (Tree[x]==-1 ) return x;else {int tmp=findFather (Tree[x]);return tmp;bool cmp (Edge x,Edge y) return x.cost<y.cost;int main () int N;while (cin>>N&&N)for (int i=0 ;i<5000 ;i++)0 ;int M=N*(N-1 )/2 ;for (int i=0 ;i<M;i++)sort (edge,edge+M,cmp);init ();int ans=0 ;for (int i=0 ;i<M;i++)int a=findFather (edge[i].a);int b=findFather (edge[i].b);if (a!=b) return 0 ;
最短路径 自己到自己设为0 其他一开始设为-1 不可达 Floyd 弗洛伊德算法 全源最短路 三重循环
1 2 3 4 5 6 7 for(int k=1;k<=n;k++) //k从1到N循环,依次代表允许经过的中间结点编号小于等于k
算法特点:最好图的大小不超过200个结点,当两个结点间有多余一条边时,选择长度最小的边权值存入邻接矩阵。
Dijkstra 迪杰斯特拉算法 单源最短路
算法流程:
初始化,集合K中加入结点1,结点1到结点1最短距离为0,到其他结点为无穷(或不确定)
遍历与集合K中结点直接相邻的边(U,V,C),其中U属于集合K,V不属于集合K,计算由结点1出发按照已经得到的最短路径到达U,再由U经过该边到达V时的路径长度。比较所有与集合K中结点直接相邻的非集合K结点该路径长度,其中路径长度最小的结点被确定为下一个最短路径确定的结点,其最短路径长度即为这个路径长度,最后将该结点加入集合K
若集合K中已经包含所有的点,算法结束;否则重复步骤2
例题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> #include <vector> using namespace std;struct E {int next; int c; 101 ];bool mark[101 ];int Dis[101 ];int main () int n,m;while (cin>>n>>m&&n&&m)for (int i=1 ;i<=n;i++) clear (); while (m--)int a,b,c;push_back (tmp);push_back (tmp);for (int i=1 ;i<=n;i++)-1 ;false ;1 ]=0 ; 1 ]=true ;int newP=1 ;for (int i=1 ;i<n;i++)for (int j=0 ;j<edge[newP].size ();j++){int t=edge[newP][j].next;int c=edge[newP][j].c;if (mark[t]==true ) continue ;if (Dis[t]==-1 ||Dis[t]>Dis[newP]+c)int min=123123123 ;for (int j=1 ;j<=n;j++){if (mark[j]==true ) continue ;if (Dis[j]==-1 ) continue ;if (Dis[j]<min){true ;return 0 ;
采用矩阵
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 需要一个辅助数组dis 来存储起点到其他所有点的距离dis 数组中的值称为最短路程的"估计值" for (int i=1;i<=n ;i++)dis [i]=a[1][i](假设起点为1)for (int i=1;i<=n ;i++)dis 数组中找当前离起点最近的点dis 数组更新起点到那些边的距离Inf ;for (int i=1;i<=dis .size();i++)if (dis [i]<min)dis [i];mark =i ;for (int v=1;v<=n ;v++)if (a[mark ][v]<inf )if (dis [v]>dis [mark ]+a[mark ][v])dis [v]=dis [mark ]+a[mark ][v];n -1所以最外层还要加上循环for (int k=1;k<=n -1;k++)n ^2)
拓扑排序 使用标准模版:std::queue
Q.push(x);将元素x放入队尾
x=Q.front();//读取队头元素,将其值赋值给x
Q.pop();//弹出队头元素
Q.empty();//判断队列是否为空,若返回值为true代表队列为空
为了保存在拓扑排序中不断出现的和之前已经出现的入度为 0 的结点,我们 使用一个队列。每当出现一个入度为 0 的结点,我们将其放入队列;若需要找到 一个入度为 0 的结点,就从队头取出。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 // 在一个 qq 群里有着许多师徒关系,如 A 是 B 的师父,同时 B// 是A的徒弟,一个师父可能有许多徒弟,一个徒弟也可能会有许多不同的师父。 // 输入给出该群里所有的师徒关系,问是否存在这样一种非法的情况:// 以三个人为 例,即A是B的师父,B是C 的师父,C又反过来是A的师父。// 若我们将该群 里的所有人都抽象成图上的结点,将所有的师徒关系都抽象成有向边(由师父指 向徒弟),// 该实际问题就转化 图是否为有向无环图。为一个数学问题——该图上是否存在一个环,// 即判断是否属于有向无环图时。若一个图,存在符合拓扑次序的结点序列,则该图为有向无环图501 ];// 邻接链表,此边无权值,只需保存编号// 保存入度为0 的结点的队列501 ];// 统计每个结点的入度while (cin>>n>>m&&n&&m)for (int i=0 ;i<n;i++)// 初始化所有结点,编号0 ~n-1 0 ; // 初始化入度信息,所有结点入度均为0 // 清空邻接链表while (m--)// 读入一条由a指向b的有向边// 将b加入a的邻接链表while (Q.empty()==false) Q.pop();// 清空队列for (int i=0 ;i<n;i++){if (inDegree[i]==0 )// 若结点入度为0 ,则将其放入队列0 ;// 累加已经确定拓扑序列的结点个数while (Q.empty()==false){// 取出队头结点编号// 弹出队头元素for (int i=0 ;i<edge[nowP].size();i++){// 将该结点以及以其为弧尾的所有边去除// 去除某条边后,该边所指后继结点入度减一if (inDegree[edge[nowP][i]]==0 ){// 若该结点入度变为0 // 将其放到队列中// 若所有结点都能被确定拓扑序列,则原图为有向无环图// 否则,原图为非有向无环图if (cnt==n) cout<<"YES" ;else cout<<"NO" ;0 ;