mlagent学习记录
记录mlagent相关知识
工作流程
ML-Agents Academy类按如下方式安排代理模拟循环:
1.调用学院的OnEnvironmentReset委托。
2.为场景中的每个Agent调用OnEpisodeBegin()函数。
3.为场景中的每个Agent调用 CollectObservations(VectorSensor sensor)函数。
4.使用每个Agent的策略来决定Agent的下一个动作。
5.为场景中的每个Agent调用OnActionReceived()函数,并传入代理商策略选择的操作。
6.如果代理已达到其 MaxStep ,则调用代理的OnEpisodeBegin()函数。
命令行相关
使用mlagents-learn进行训练
相应参数: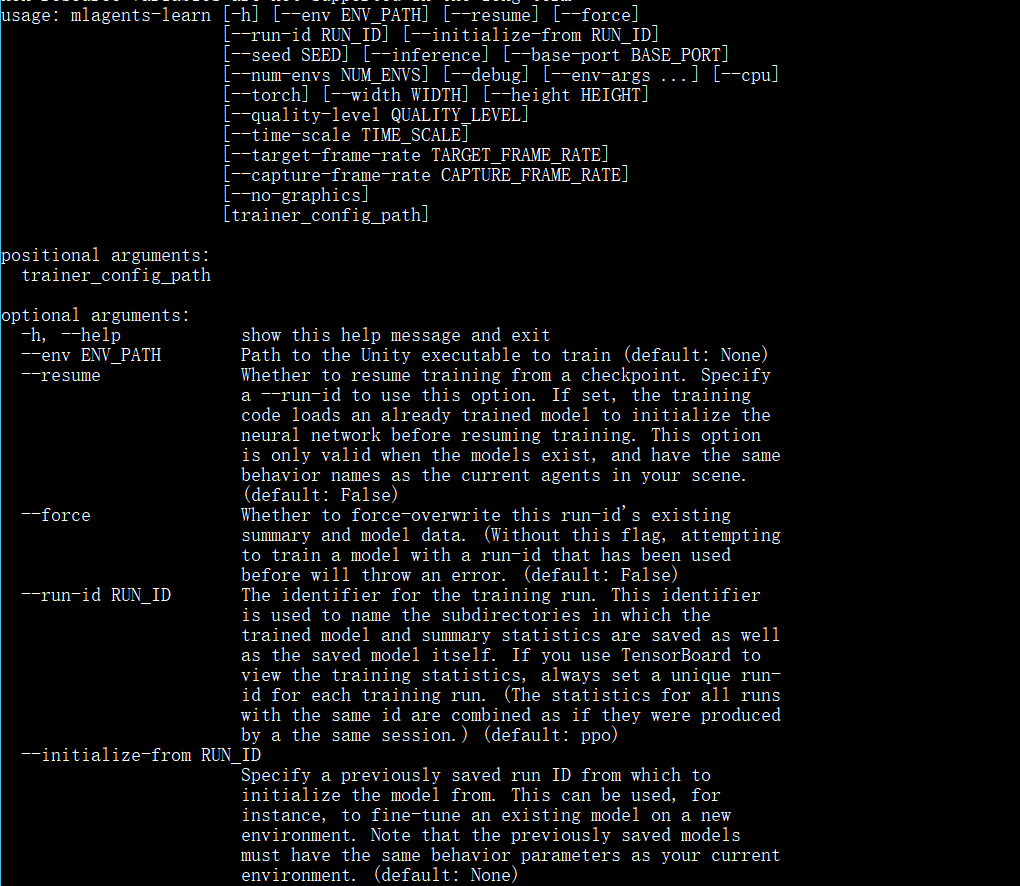
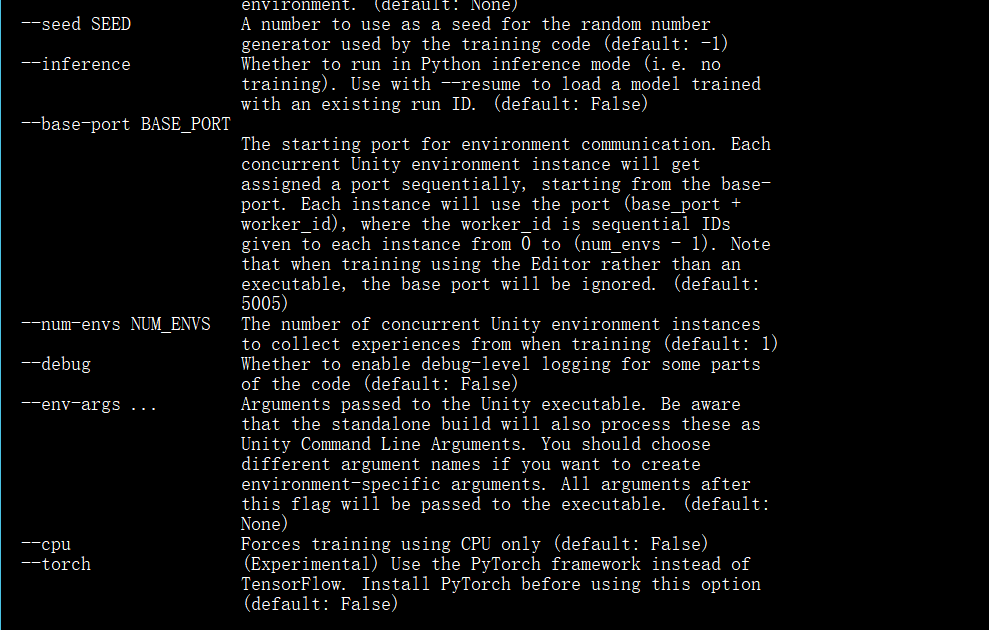
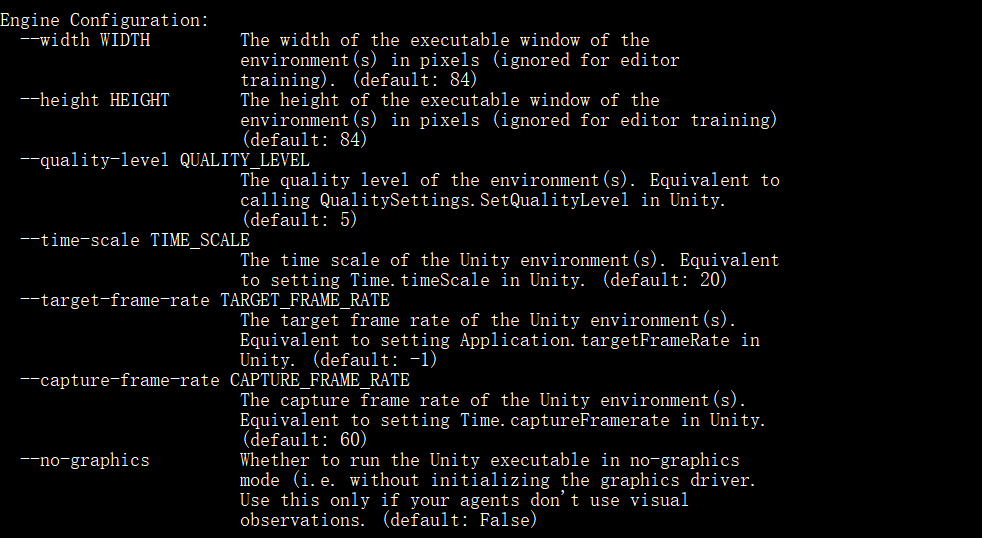
设计Agent
Agent
代理扮演这观察周围环境,并决定最好的使用这些观察的行动方针的角色。通过在unity中继承Agent类来创建Agent。创建Agent的关键是你根据Agent完成任务并给予的奖励。
一个Agent将它观察到的信息传给它的Policy。之后,Policy会做出决定并且反馈相应的动作给Agent。你的Agent代码必须执行这个动作并对每个动作评估奖励值,奖励值用来探索最优的决策。
Policy从代理本身抽象出决策逻辑,因此您可以在多个代理中使用相同的策略。政策如何制定决策取决于它是什么样的政策。您可以更改策略
通过更改其”行为参数(Behavior Parameters)”来代理。如果您将”行为类型(Behavior Type)”设置为”仅限启发式(Heuristic Only)”,代理将使用其”启发式”方法做出决策它可以允许您手动控制代理或编写自己的策略。如果代理有一个”模型(Model)”文件,它的政策将使用神经网络”模型”作出决定。
Decisons
每次代理请求时,观察-决策-行动-奖励周期都会重复一个决定。当”Agent.RequestDecision()”被调用时,代理将请求决策。如果您需要代理定期请求自行决策,添加代理游戏对象的”Decision Requester”组件。定期决策
间隔通常最适合基于物理的模拟。例如,机器人模拟器中的代理,必须提供关节扭矩的精细控制应该在模拟的每一步都做出决定。另一方面,一个代理,只需要作出决定时,某些游戏或模拟事件发生,应手动调用”Agent.RequestDecision()”。
Observations
要做出决策,代理必须观察其环境才能推断世界的状态。状态观察可以采取以下形式:
- Vector Observation : 由浮点数组成的数组
- Visual Observation : 一个或多个摄像机图像或者渲染纹理
当你使用vector Observation时,要继承Agent.CollectObservations(VectorSensor sensor)方法来创建功能矢量
当你使用visual Observation时,你只需要确定哪些Unity的相机对象或渲染将提供图像,基础代理类将处理剩下的东西。你不需要使用CollectObservations(VectorSensor sensor)方法,除非你也同时使用了vector observation。
Vector Observation Space: Feature Vectors
使用CollectObservations(VectorSensor sensor)方法来收集信息在这个函数里面使用VectorSensor.AddObservation 来手动添加信息。
例如:
1 | |
当设置Agent的Behavior Parameters时,可以设置下面这些属性:
- Space Size: 状态大小必须匹配你之前添加信息构成的功能矢量的长度,
观测特征向量是浮点数列表,这意味着
您必须将任何其他数据类型转换为浮点数或浮点数列表。VectorSensor.AddObservation方法提供许多通用类型的数据载入,你可以添加整数和布尔类型的数据,也可以添加unity中的数据类型Vector2,Vector3, andQuaternion.
类型列举应以_one hot_样式进行编码。即,添加一个每个列举元素的功能载体的元素,设置将观察到的成员代表为一个的元素,并将其余部分设置为零。
Normalization
为了在培训时取得最佳效果,您应该使培训的组件规范化。
功能矢量的范围[-1,+1]或[0,1]。当您使值规范化时,PPO神经网络通常可以更快地融合到解决方案。请注意,并不一定总是要的归一画到这些推荐的范围,但它是在使用神经网络时被认为是最佳实践。在您的观察组件之间的范围内变化越大,培训将更有可能受到影响。
为了归一化数值到值[o,1],可以使用下面的公式
1 | |
旋转和角度也同样要归一化,当角度位于0到360度之间时,可以使用下面的公式
1 | |
对于可能超出[0,360]范围的角度,您可以减小角度,或者,如果转数很大,则增加最大值(maximum value).
Multiple Visual Observations
视觉观察直接或从一个或多个中使用渲染的纹理场景中的摄影机。 该策略将纹理矢量化为3D张量可以馈入卷积神经网络(CNN)。可以将视觉观察与辅助向量观察一起使用。使用视觉观察的代理可以捕获任意复杂度的状态,并且当状态难以用数字描述时,此功能很有用。 但是,他们通常也效率较低,训练较慢,有时甚至不
完全成功。
视觉观察结果可以从场景中的Cameras或RenderTextures中获取。要将视觉观察添加到代理,请添加“摄像机传感器”组件或将RenderTextures传感器组件添加到代理。
然后拖动相机或渲染要添加到Camera或RenderTexture字段的纹理。您可以拥有多个摄像头或渲染纹理,甚至可以结合使用都附加到代理。 对于每个视觉观察,设置宽度和高度
图像的像素数(以像素为单位)以及观察结果是彩色还是灰度。
使用相同策略的每个代理程序必须具有相同数量的视觉观察结果,并且它们都必须具有相同的分辨率(包括它们是否为灰度)。此外,代理上的每个传感器组件都必须具有唯一的名称,以便它们可以确定性地排序(该名称对于该Agent必须是唯一的,但是多个Agent可以
具有相同名称的传感器组件)。
当使用RenderTexture视觉观察时,方便的调试功能是
添加一个“画布”,然后添加一个“原始图像”,并将其纹理设置为代理的RenderTexture。 这将在游戏屏幕上呈现Agent观察图像。
可以参考 GridWord 项目使用情况(官方案例),目的是到达指定地点同时避免碰撞。
Raycast Observations
只需添加一个RayPerceptionSensorComponent3D(RayPerceptionSensorComponent2D)在观察过程中,几条光线(或球体,取决于设置)被投射到物理世界,被击中的物体决定了生成的观察向量。
Both sensor components have several settings:
- Detectable Tags 对应于代理应该能够区分的对象类型的字符串列表。 例如,在WallJump示例中,我们使用“墙”,“目标”和“块”作为要检测的对象列表。
- Rays Per Direction 确定投射的光线数。一缕是总是向前投射,多的光线向左右投射。
- Max Ray Degrees 最外面的光线的角度(以度为单位)。 90度对应代理的左侧和右侧。.
- Sphere Cast Radius 用于球体铸造的球体的大小。 如果设置到0,将使用射线代替球体。 光线可能更有效,特别是在复杂的场景中。
- Ray Length 射线长度
- Observation Stacks 要与转换结果“堆叠”的先前结果数。 请注意,这可以独立于“行为参数”中的“堆叠矢量”设置。
- Start Vertical Offset (3D only) 射线起点的垂直偏移。
- End Vertical Offset (3D only) 射线终点的垂直偏移.
创建的观测值的总大小为
1 | |
因此,应尽量减少射线和标签的数量,以减少使用的数据量。 请注意,这与在Behavior Parameters中状态大小无关。
Vector Actions
动作是代理执行的来自策略的指令。 当学院调用时,会将操作作为参数传递给代理。使用OnActionReceived()。当您指定矢量动作空间时
是 Continuous,则传递给Agent的action参数是一个数组
长度等于Vector Action Space Size属性的控制信号。当您指定Discrete向量动作空间类型时,该动作参数是包含整数的数组。 每个整数都是列表或表的索引
命令。
在Discrete向量动作空间类型中,动作参数是一个索引数组。 数组中的索引数由
在Branches Size属性中定义的数决定。每个分支对应于一个动作表,您可以通过指定每个表的大小修改Branches属性。
Policy和培训算法都不知道有关该采取的行动本身的意思。训练算法只是尝试
动作列表中不同的值并观察随着时间的推移这些值对累积奖励的影响。因此,为Agent定义的唯一位置动作是在OnActionReceived()函数中。
例如,如果您设计了一个可以在两个维度上移动的代理,则可以使用连续或离散矢量动作。 在连续的情况下,您会将向量动作大小设置为2(每个维度一个),并且代理的策略将创建一个具有两个浮点值的操作。在离散情况下,您将使用一个大小为4的分支(每个分支一个)
方向),该策略将创建一个包含单个值范围从零到三的元素。 或者,您可以创建大小为2的两个分支(一个用于水平移动,一个用于垂直移动),并且该策略将创建一个包含两个元素的操作数组,值范围从零到一。
请注意,在为代理编程操作时,通常有助于使用代理的Heuristic()方法测试您的操作逻辑,让您映射键盘行动命令。
The 3DBall and Area example environments are set up to use either the continuous or the discrete vector action spaces.
Continuous Action Space
当代理使用设置为“连续”向量操作空间的策略时,传递给代理的OnActionReceived()函数的操作参数是一个数组长度等于“矢量操作空间大小”属性值。数组中的各个值具有您赋予的任何含义.
默认情况下,我们提供的PPO算法的输出会预先钳制vectorAction进入[-1,1]范围。 最佳做法是手动剪辑如果您打算在您的环境中使用第三方算法,则也需要这些。
Discrete Action Space
如果Agent使用 Discrete向量操作空间,则传递给代理的OnActionReceived()函数的操作参数是一个包含索引的数组。在离散向量作用空间中,Branches是一个
整数数组,每个值对应于每个分支。
例如,如果我们想要一个可以在平台上移动并跳跃的Agent,我们可以
定义两个分支(一个代表运动,一个代表跳跃),因为我们想要
代理能够同时移动 和 跳。 我们定义第一个分支有5种可能的动作(不要移动,左移,右移,后退,前进),第二个动作有2种可能的动作(不要跳,跳)。 这
OnActionReceived()方法类似于:
1 | |
以上代码示例是AreaAgent的简化摘录类,离散量和连续动作空间都有。
Masking Discrete Actions
使用离散动作时,可以指定某些动作为下一个决定是不可能采用的。 当代理受
神经网络控制时,代理将无法执行指定的操作。 注意当代理受Heuristic启发式控制时,代理将仍然能够决定执行屏蔽操作。 为了掩盖动作,请覆盖Agent.CollectDiscreteActionMasks()虚拟方法,并在其中调用DiscreteActionMasker.SetMask():
1 | |
Where:
branchis the index (starting at 0) of the branch on which you want to mask the actionactionIndicesis a list ofintcorresponding to the
indices of the actions that the Agent cannot perform.
例如,如果您有一个具有2个分支的代理,并且在第一个分支
(分支0)有4种可能的操作:_“什么都不做” _,_“跳转” _,_“拍摄” _
和_“更换武器” _。 然后使用下面的代码,代理将_“ do
对于他的下一个决定,无“ _”或“更换武器” _(因为动作索引1和2
被遮罩)
1 | |
注意:
- You can call
SetMaskmultiple times if you want to put masks on
multiple branches. - You cannot mask all the actions of a branch.
- You cannot mask actions in continuous control.
Rewards
在强化学习中,奖励是Agent做正确事情的信号。 PPO强化学习算法通过优化代理做出的选择来工作,以使代理随时间获得最高的累积奖励。 您的奖励机制越好,您的代理商将学得越好。
注意:
奖励在Agent使用经过训练的模型进行推理时不会使用,在模仿学习中也不会使用。
也许最好的建议是从简单开始,仅在需要时增加复杂性。 通常,您应该奖励结果,而不是您认为会导致期望结果的行动。 为了帮助您获得奖励,您可以使用Monitor类显示代理收到的累积奖励。 您甚至可以在观察代理如何累积奖励的同时,使用代理的启发式方法来控制代理。
通过调用OnActionReceived()函数中的AddReward()方法向代理分配奖励。 每个决策之间分配的奖励应在[-1,1]范围内。 超出此范围的值可能导致训练不稳定。 当Agent收到新决定时,reward值将重置为零。 如果对一个代理决策有多个对AddReward()的调用,则将这些奖励加起来以评估前一个决策的质量。 有一种名为SetReward() ”的方法,该方法将覆盖自上一个决定以来给予代理的所有先前奖励。
Agent Properties
Behavior Parameters- The parameters dictating what Policy the Agent will
receive.Behavior Name- 行为的标识符。 具有相同行为名称的代理将学习相同的政策.Vector ObservationSpace Size- Agent的向量观测值的长度。Stacked Vectors- 将被堆叠并一起用于决策的先前矢量观测的数量。 这导致矢量观察的有效大小被传递给策略为:Space Size x _Stacked Vectors_。
Vector ActionSpace Type- 对应于动作矢量是否包含单个整数(离散)或一系列实值浮点(连续).Space Size(Continuous) - 动作向量的长度.Branches(Discrete) - 整数数组,定义多个并发的离散操作。 “分支”数组中的值对应于每个操作分支的可能离散值的数量。
Model- 用于推理的神经网络模型(训练后获得)Inference Device- 在推理期间使用CPU还是GPU运行模型Behavior Type- Determines whether the Agent will do training, inference, or use its
Heuristic() method:Default- the Agent will train if they connect to a python trainer, otherwise they will perform inference.Heuristic Only- the Agent will always use theHeuristic()method.Inference Only- the Agent will always perform inference.
Team ID- Used to define the team for self-playUse Child Sensors- Whether to use all Sensor components attached to child GameObjects of this Agent.
Max Step- 每个代理的最大步骤数。 一旦这个数字到达后,代理将被重置.
训练 Agent
训练过程的输出是一个包含优化后的模型文件政策。 该模型文件是TensorFlow数据图,其中包含数学训练过程中选择的最佳操作和最佳权重。 使用命令mlagents-learn 来训练您的代理。 此命令已安装在mlagents软件包。可在以下位置找到ml-agents / mlagents / trainers / learn.py。
可以像config / trainer_config.yaml这样编辑配置文件指定训练期间使用的超参数。您可以使用文本编辑器编辑此文件,以添加特定的配置
每个行为。
1 | |
在训练过程中,训练程序会定期间隔(由summary_freq选项指定)打印和保存更新。 保存的信息按run-id值分组,因此您应该为每个ID分配一个唯一的ID。
您可以在训练期间或之后通过运行以下命令使用TensorBoard查看这些统计信息
1 | |
之后本地浏览器打开 http://localhost:6006.
注意:
TensorBoard使用的默认端口是6006。如果存在现有会话在端口6006上运行,可以使用–port在开放的端口上启动新会话选项。
训练结束后,您可以在models 文件夹中在指定的运行ID下找到保存的模型
Training Config File
| Setting | Description | Applies To Trainer* |
|---|---|---|
| batch_size | The number of experiences in each iteration of gradient descent. | PPO, SAC |
| batches_per_epoch | In imitation learning, the number of batches of training examples to collect before training the model. | |
| beta | The strength of entropy regularization. | PPO |
| buffer_size | The number of experiences to collect before updating the policy model. In SAC, the max size of the experience buffer. | PPO, SAC |
| buffer_init_steps | The number of experiences to collect into the buffer before updating the policy model. | SAC |
| epsilon | Influences how rapidly the policy can evolve during training. | PPO |
| hidden_units | The number of units in the hidden layers of the neural network. | PPO, SAC |
| init_entcoef | How much the agent should explore in the beginning of training. | SAC |
| lambd | The regularization parameter. | PPO |
| learning_rate | The initial learning rate for gradient descent. | PPO, SAC |
| learning_rate_schedule | Determines how learning rate changes over time. | PPO, SAC |
| max_steps | The maximum number of simulation steps to run during a training session. | PPO, SAC |
| memory_size | The size of the memory an agent must keep. Used for training with a recurrent neural network. See Using Recurrent Neural Networks. | PPO, SAC |
| normalize | Whether to automatically normalize observations. | PPO, SAC |
| num_epoch | The number of passes to make through the experience buffer when performing gradient descent optimization. | PPO |
| num_layers | The number of hidden layers in the neural network. | PPO, SAC |
| behavioral_cloning | Use demonstrations to bootstrap the policy neural network. See Pretraining Using Demonstrations. | PPO, SAC |
| reward_signals | The reward signals used to train the policy. Enable Curiosity and GAIL here. See Reward Signals for configuration options. | PPO, SAC |
| save_replay_buffer | Saves the replay buffer when exiting training, and loads it on resume. | SAC |
| sequence_length | Defines how long the sequences of experiences must be while training. Only used for training with a recurrent neural network. See Using Recurrent Neural Networks. | PPO, SAC |
| summary_freq | How often, in steps, to save training statistics. This determines the number of data points shown by TensorBoard. | PPO, SAC |
| tau | How aggressively to update the target network used for bootstrapping value estimation in SAC. | SAC |
| time_horizon | How many steps of experience to collect per-agent before adding it to the experience buffer. | PPO, SAC |
| trainer | The type of training to perform: “ppo”, “sac”, “offline_bc” or “online_bc”. | PPO, SAC |
| train_interval | How often to update the agent. | SAC |
| num_update | Number of mini-batches to update the agent with during each update. | SAC |
| use_recurrent | Train using a recurrent neural network. See Using Recurrent Neural Networks. | PPO, SAC |
Training with Proximal Policy Optimization
ML-Agents提供一种称为近端策略优化(PPO)的强化学习算法的实现。 PPO使用神经网络来逼近理想功能,该理想功能将代理的观察结果映射到代理在给定状态下可以采取的最佳操作。 ML-Agents PPO算法在TensorFlow中实现,并在单独的Python进程中运行(通过套接字与正在运行的Unity应用程序进行通信)。成功训练强化学习模型通常涉及调整训练超参数。 本指南包含一些最佳实践,用于在默认参数似乎无法达到您想要的性能水平时调整培训过程。
Hyperparameters
Reward Signals
在强化学习中,目标是学习使奖励最大化的策略。在基础级别上,奖励是由环境给予的。 但是,我们可以想象奖励代理商各种不同的行为。 例如,我们可以奖励代理商探索新状态,而不仅仅是给出明确的奖励。 此外,我们可以混合奖励信号来帮助学习过程。
ML-Agents工具箱默认提供三个奖励信号:外部(环境)奖励信号,好奇心奖励信号(可用于鼓励在稀疏外部奖励环境中进行探索)和GAIL奖励信号。
1 | |
除了任何特定于类的超参数之外,每个奖励信号还应至少定义两个参数“ strength”和“ gamma”。 请注意,要删除奖励信号,您应该从“ reward_signals”中完全删除其条目。 任何时候都应至少定义一个奖励信号。
Reward Signal Types:
Strength:Typical Range:1.0
Gamma: Typical Range:0.8-0.995Curiosity Reward Signal:
Strength:Typical Range:0.001-0.1
Gamma: Typical Range:0.8-0.995
encoding_size:encoding_size对应于固有好奇心模型使用的编码大小。此值应足够小以鼓励ICM压缩原始观察结果,但也不能太小以防止其学习区分已演示和实际行为。Default Value:64。Typical Range:64-256GAIL Reward Signal:
Strength:Typical Range:0.01-1.0
Gamma: Typical Range:0.8-0.9
demo_path:demo_path是您的.demo文件或.demo文件目录的路径。
encoding_size:encoding_size对应于鉴别器使用的隐藏层的大小,该值应足够小以鼓励鉴别器压缩原始观测值,但也不能太小以防止其学习区分已证明的行为和实际行为。 大幅增加此大小也会对训练时间产生负面影响。 Default Value:64Typical Range:64-256
Lambda
lambd对应于计算通用优势估算值([GAE](https://arxiv.org/abs/1506.02438))时使用的“ lambda”参数。 这可以认为代理在计算更新的价值估算时多少依赖于其当前价值估算。 低值对应于更多地依赖于当前值估计(可能是高偏差),而高值对应于更多地依赖于在环境中接收到的实际奖励(可能是高方差)。 参数提供了两者之间的折衷,正确的值可以导致更稳定的训练过程。
Typical Range: 0.9 - 0.95
Buffer Size
buffer_size对应于我们进行任何模型学习或更新之前应收集的经验(代理商的观察,行动和获得的奖励)的数量。 **这应该是batch_size**的倍数。 通常,较大的buffer_size对应于更稳定的训练更新。
Typical Range: 2048 - 409600
Batch Size
batch_size是用于梯度下降更新的一次迭代的经验数量。 **这应该始终是buffer_size**的一小部分。 如果您使用的是连续动作空间,则该值应较大(大约1000s)。 如果您使用的是离散操作空间,则该值应较小(约10s)。
Typical Range (Continuous): 512 - 5120
Typical Range (Discrete): 32 - 512
Number of Epochs
num_epoch是梯度下降过程中通过experience buffer的次数。 batch_size越大,可以接受的越大。 减少此设置将确保更新更稳定,但会降低学习速度。
Typical Range: 3 - 10
Learning Rate
learning_rate对应于每个梯度下降更新步骤的强度。 如果训练不稳定,则通常应减少该奖励,并且奖励不能持续增加。
Typical Range: 1e-5 - 1e-3
(Optional) Learning Rate Schedule
learning_rate_schedule对应于学习率随时间的变化。对于PPO,我们建议递减学习率直到max_steps以便学习更稳定地收敛。 但是,在某些情况下(例如,训练时间未知),可以禁用此功能。
Options:
linear(default): 线性衰减learning_rate,在max_steps处达到0。constant: 在整个训练过程中保持学习率恒定.
Options: linear, constant
Time Horizon
time_horizon对应于将每个代理添加到体验缓冲区之前收集多少个体验步骤。 在episode结束之前达到此限制时,将使用价值估算值来预测业务代表当前状态的总体预期回报。 因此,此参数在偏见程度较小但方差估计较高(较长时间范围)与偏倚较大但变化较少的估计值(较短时间范围)之间进行权衡。 如果情节中频繁获得奖励,或者情节过长,
数字越小越理想。 此数字应足够大,以捕获代理程序动作序列中的所有重要行为。
Typical Range: 32 - 2048
Max Steps
max_steps对应于训练过程中运行了多少步仿真(乘以跳帧)。 对于更复杂的问题,应该增加该值。
Typical Range: 5e5 - 1e7
Beta
beta对应于熵正则化的强度,这使策略“更加随机”。 这样可以确保座席在训练过程中正确探索动作空间。 增加此数量将确保采取更多随机动作。 应当对此进行调整,以使熵(可从TensorBoard测量)随着奖励的增加而缓慢减小。 如果熵下降太快,则增加beta。 如果熵下降太慢,则降低beta。.
Typical Range: 1e-4 - 1e-2
Epsilon
epsilon 对应于梯度下降更新期间新旧策略之间可接受的差异阈值。 将此值设置得较小将导致更稳定的更新,但也会减慢训练过程。
Typical Range: 0.1 - 0.3
Normalize
normalize 对应于是否对矢量观测输入应用了归一化。 该归一化基于矢量观测值的移动平均值和方差。 规范化对于复杂的连续控制问题很有用,但对于较简单的离散控制问题则可能有害。
Number of Layers
num_layers对应于观察输入之后或视觉观察的CNN编码之后存在多少个隐藏层。 对于简单的问题,较少的层可能会更快更有效地进行训练。 对于更复杂的控制问题,可能需要更多的层。
Hidden Units
hidden_units 对应于神经网络的每个完全连接层中有多少个单元。 对于简单的问题,其中正确的操作是观察输入的直接组合,这应该很小。 对于动作是观察变量之间非常复杂的相互作用的问题,此值应该更大。
Typical Range: 32 - 512
(Optional) Visual Encoder Type
vis_encode_type对应于用于对视觉观察进行编码的编码器类型。
有效选项包括:
simple(默认):一个简单的编码器,由两个卷积层组成nature_cnn:[Mnih等人提出的CNN实现](https://www.nature.com/articles/nature14236),
由三个卷积层组成resnet:[IMPALA Resnet实施](https://arxiv.org/abs/1802.01561),
由三层堆叠的层组成,每层有两个残余块,
比其他两个更大的网络。
选项:simple,nature_cnn,resnet
(Optional) Recurrent Neural Network Hyperparameters
以下超参数仅在use_recurrent设置为true时使用
Sequence Length
sequence_length 对应于训练期间通过网络传递的经验序列的长度。 该时间应足够长,以捕获代理随时间推移可能需要记住的任何信息。 例如,如果您的Agent需要记住物体的速度,则此值可能很小。 如果您的经纪人只需要记住一集开始时只给出一次的信息,则该值应该更大。
Typical Range: 4 - 128
Memory Size
memory_size对应于用于存储策略循环神经网络隐藏状态的浮点数数组的大小。 该值必须是2的倍数,并且应该与您期望代理成功完成任务所需记住的信息量成比例。
Typical Range: 32 - 256
(Optional) Behavioral Cloning Using Demonstrations
在某些情况下,您可能想使用播放器记录的行为来引导代理策略。 这可以帮助指导代理商获得奖励。 行为克隆(BC)增加了模仿示范的训练操作,而不是试图使报酬最大化。
要使用BC,请在trainer_config中添加一个“ behavioral_cloning”部分。 例如:
1 | |
以下是BC可用的超参数。
Strength
strength对应于模仿的学习率相对于PPO的学习率,大致对应于我们允许BC影响政策的强度。
Typical Range: 0.1 - 0.5
Demo Path
demo_path是您的.demo文件或.demo文件目录的路径。 有关.demo文件的更多信息,请参见Training-Imitation-Learning.md(官方文档)。
Steps
在BC期间,通常希望代理在“看到”奖励后停止使用演示,并允许其优化过去的可用演示和/或泛化所提供的演示之外的内容。
steps对应于BC有效的训练步骤。 BC的学习率将逐步逐步提高。 将步骤设置为0,以在整个训练过程中持续模仿。
(Optional) Batch Size
batch_size是用于梯度下降更新的一次迭代的演示经验的数量。 如果未指定,则默认为为PPO定义的batch_size。
Typical Range (Continuous): 512 - 5120
Typical Range (Discrete): 32 - 512
(Optional) Number of Epochs
num_epoch是梯度下降过程中通过体验缓冲区的次数。 如果未指定,则默认为PPO设置的时期数。
Typical Range: 3 - 10
(Optional) Samples Per Update
samples_per_update 是最大样本数
在每次模仿更新期间使用。 如果您的演示数据集非常大,则可能需要降低此值,以避免过分适合演示策略。 设置为0可在每个更新步骤训练所有演示。
Default Value: 0 (all)
Typical Range: Approximately equal to PPO’s buffer_size
Training Statistics
要查看训练统计信息,请使用TensorBoard。
Cumulative Reward
随着时间的流逝,奖励的总体趋势应持续增加。 预计会有小起起落。 根据任务的复杂性,奖励可能不会显着增加,直到进入培训过程的数百万步为止。
Entropy
这对应于决策的随机性。 在训练期间,这应该持续减少。 如果它减小得太快或根本没有减小,则应调整beta(使用离散动作空间时)。
Learning Rate
默认情况下,这会随着时间的流逝而减少,除非将learning_rate_schedule设置为constant。
Policy Loss
这些值会在训练过程中振荡。 通常,它们应小于1.0。
Value Estimate
这些值应随着累积奖励的增加而增加。 它们对应于Agent预测自己在任何给定时间点会收到多少奖励。
Value Loss
这些价值将随着奖励的增加而增加,一旦奖励稳定就应减少。
实例 Gridworld

- 设置:经典网格世界任务的版本。场景包含代理商,目标,
和障碍。 - 目标:代理商必须在网格上导航至目标,同时避免
障碍。 - 代理:环境包含九个具有相同行为参数的代理。
- Agent奖励功能:
- -0.01每一步。
- +1.0,如果座席导航到网格的目标位置(情节结束)。
- -1.0,如果特工导航到障碍物(情节结束)。
- 行为参数:
- 向量观察空间:无
- 向量动作空间:(离散)大小为4,对应于运动
基本方向。请注意,对于这种环境,
[动作遮罩](Learning-Environment-Design-Agents.md#masking-discrete-actions)
默认情况下处于打开状态(此选项可以切换
使用“ trueAgent” GameObject中的“屏蔽动作”复选框。
提供的经过训练的模型文件是在启用操作屏蔽的情况下生成的。 - 视觉观察:对应于GridWorld的自顶向下视图。
- 浮动属性:三个,分别对应于网格大小,障碍物数量和
目标数。 - 基准平均奖励:0.8