数据关联分析
数据关联分析
今日学习了第三章和第四章
第三章数据可视化暂且不提
第四章数据关联分析
基本概念
频繁模式和关联规则的广泛应用为数据分析的研究和机器学习的发展起到了极大的推动作用
频繁模式可以进一步描述成数据对象间的关联规则
判断序列模式是否频繁使用两个基本的度量:
支持度:模式的有用性
置信度:规则的确定性
频繁项集和关联规则
项集:项的集合,
包含k个项的项集称为k项集,项集的出现频数是包含项集的事务数
支持度:在所有的事务中同时出现某项的概率:
support(A)=${count(A \in T)} \over{|D|}$
频繁项集:出现次数到一定程度,大于最小支持度阈值
关联规则:A→B中A,B分别称为关联规则的前件,后件
在事务集D中,对某条关联规则而言,其支持度s表示在所有的事务中同时出现A和B的概率,
即P(AB),support(A=>B)=${count(A \cup B)} \over {|D|}$
置信度:又称可信度,对A->B而言,置信度表示A出现同时B出现概率,即P(B|A)
confidence(A=>B)=${support(A \cup B)} \over {support(A)}$
如果某个关联规则同时满足最小支持度阈值和最小置信度阈值,则认为这个关联规则是有趣的
如果同时满足>=,是强关联,否则是弱关联
Aprior算法:寻找所有支持度不小于min_sup的频繁项集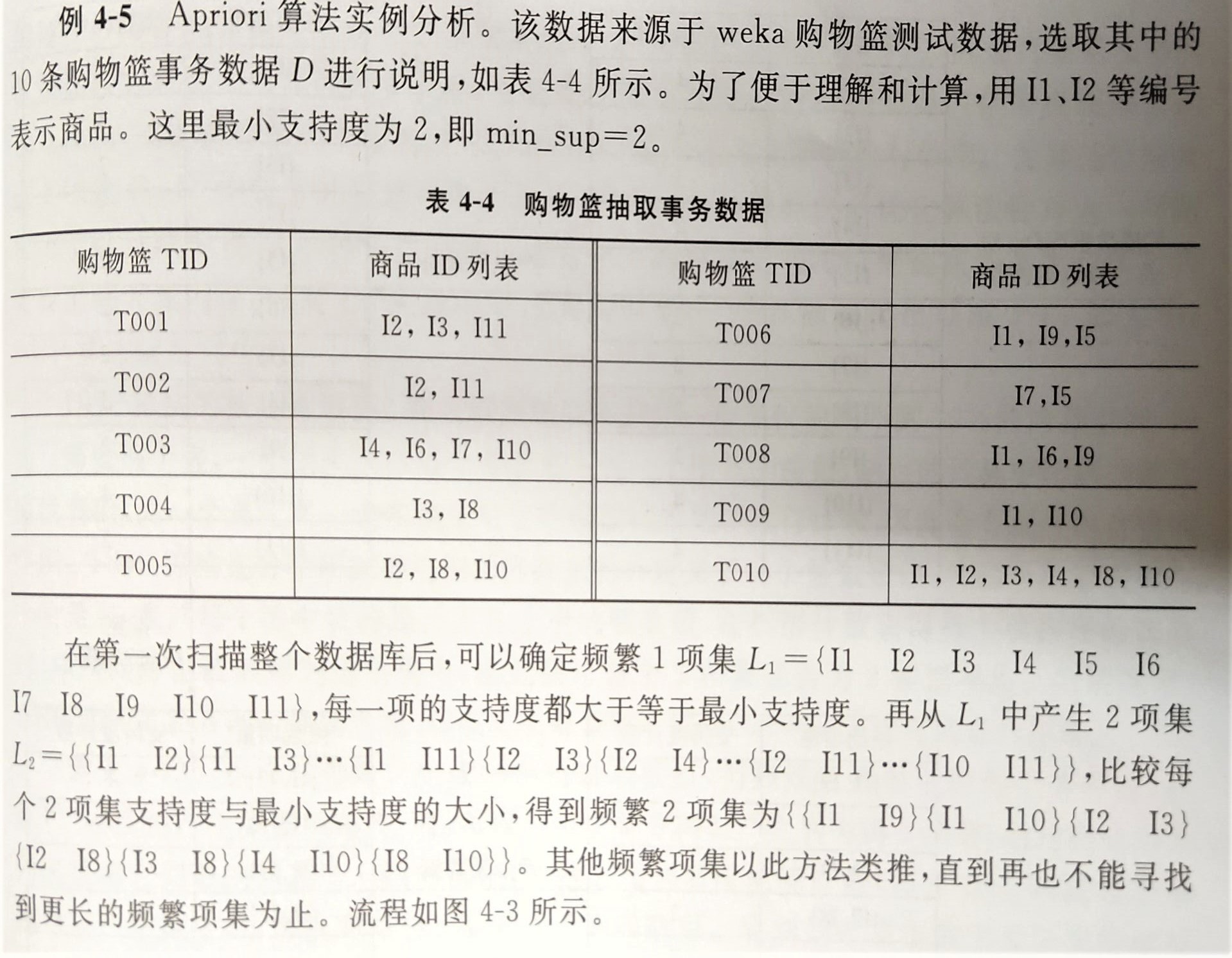
数据关联分析
https://shanhainanhua.github.io/2019/09/24/数据关联分析/